Ultracode Ate My Harness
I spent maybe a month building a five-agent harness. Then Claude Code shipped dynamic workflows that do the orchestration for free, so I raced my harness against one. On correctness they tied. The only edge my harness kept was its rubric, and a rubric is a prompt.
I spent maybe a month building an agent harness, on and off. Five roles, an adversarial review loop where one agent writes code and another grades it, an append-only trail per task, a planning layer on top. I wrote a whole post about it. Then Claude Code shipped dynamic workflows, and a chunk of what I’d hand-built turned into a stock feature.
A dynamic workflow is a short script that spawns subagents and coordinates them with plain code: loops, fan-out, a verify step. Anthropic’s post on them frames it as “a harness for every task.” Instead of one fixed pipeline, the agent writes a custom harness for the job in front of it. Their line: “Claude is now intelligent enough to write a custom harness tailor-made for your use case.”
My harness’s execution loop is the generator writes, the evaluator grades, repeat until it passes. That’s one of the patterns the post names outright: adversarial verification. When I ported my loop onto the new primitives, it came out to about ninety lines. The orchestration I’d spent a month getting right was now something the agent could write for free, per task, in a different form each time.
Autobots versus Ultracode
The real comparison isn’t “my harness versus a single agent.” It’s my harness versus a harness the agent writes on the spot and throws away when it’s done.
So what’s the difference? What does Ultracode do that my harness doesn’t? I think the biggest one is that more of the decision making on how to go about solving a problem is pushed to the model. My harness made those calls once, up front. Ultracode makes them per task.
My harness · one pipeline, every time
Five fixed roles. A rubric the evaluator scores against. A review trail and per-task commits. A month of evenings getting the architecture to hold. The same structure whether the task is a parser or a UI.
A dynamic workflow · a new one per task
A script the agent writes for the task at hand, picking from stock patterns (fan-out, adversarial verify, loop-until-done). No fixed roles. No trail unless you ask for one. Discarded after the run.
Essentially my harness ends up just being one workflow out of the series that Ultracode could choose from. After seeing it that way, I wanted to test whether my harness retained any advantage over the alternative.
I didn’t want to argue it, I wanted to check
I built three small web apps twice each: a Wordle variant with a scoring twist, an eight-by-seven Connect Four, and an expense splitter. Each one got built once by my real harness and once by a workflow Ultracode wrote fresh for that task. Same frozen spec, same starting scaffold, separate repos.
Then I graded both blind. A test suite I wrote and froze before either build ran (the duplicate-letter coloring, the diagonal win detection, the settlement math), plus a panel of judges that scored the code without knowing which build was the harness and which was the workflow.
Three apps is a probe, not a proof. But the result was clear enough to sit up for.
On correctness, they tied. Every frozen test passed by both builds, on all three apps. The harness’s extra apparatus bought nothing the tests could measure.
On quality, the blind panel split close. Two of three apps were a wash. The harness clearly won one, Connect Four, on structure and polish. But that win traced to the rubric, not the orchestration. My harness grades UI quality and structure by default, and the three checks I’d written into that particular workflow only looked at correctness. On the expense splitter, where I happened to point the workflow’s checks at the right things, the workflow matched the harness and the judges called it the more robust of the two.
Then I played all six builds myself, and I liked the workflow’s versions slightly better. Not on correctness, which tied. On the small stuff: how they look and feel, and the small nice-to-have additions that Ultracode decided to add on its own.
Take Wordle. Both score the same guess. My harness drops the round score into the row and shoves the letters out of line with the grid below. The workflow puts the score in the margin and leaves the tiles where they are. Neither is wrong. One is just tidier, and I didn’t ask either of them for that.

Connect Four is starker. My harness drops a piece only when I click a small arrow above a column, and when the game ends there’s no way to start another. The workflow lets me click anywhere in the column and gives me a New game button. My version has the slightly nicer board. The workflow’s is the one I’d rather play.
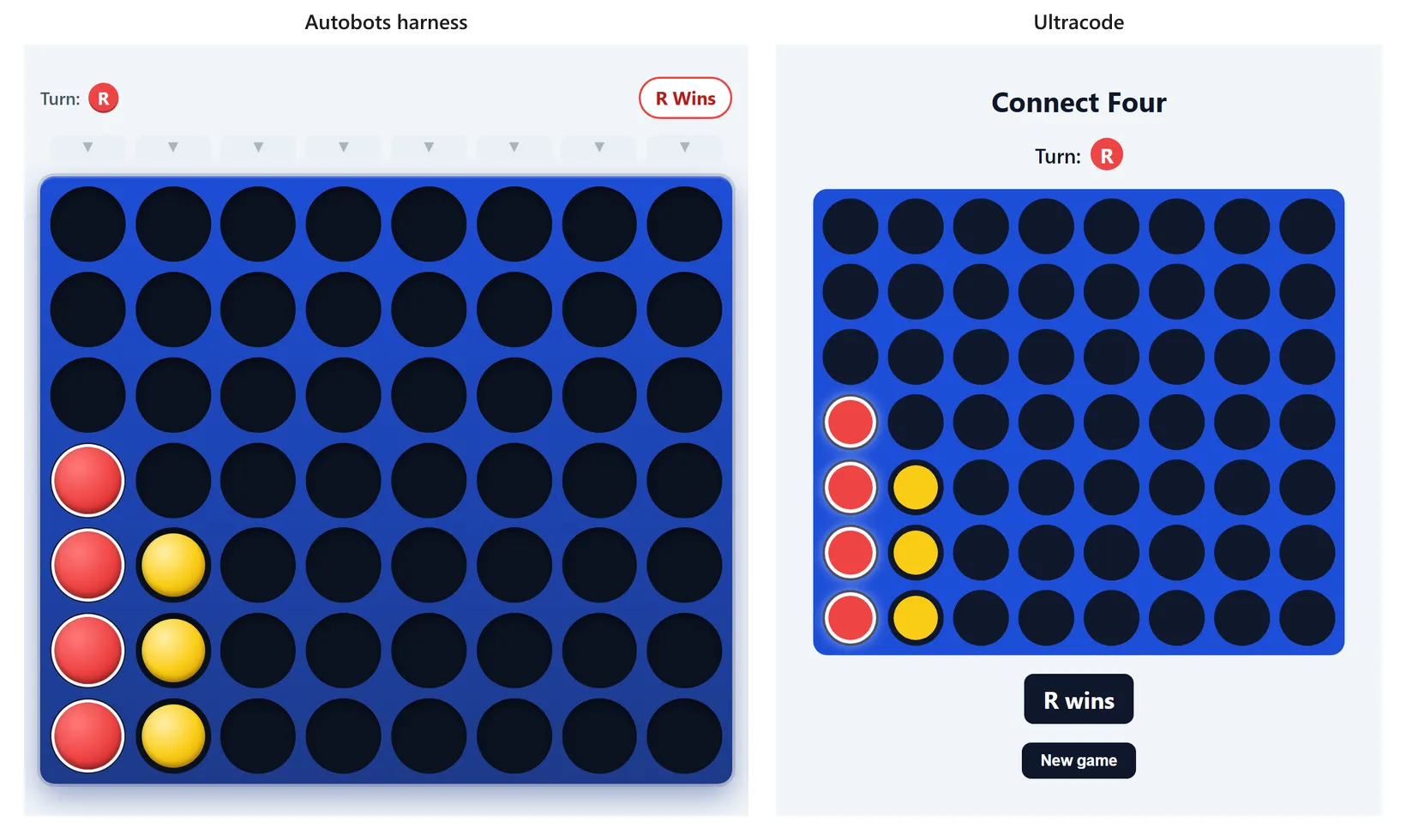
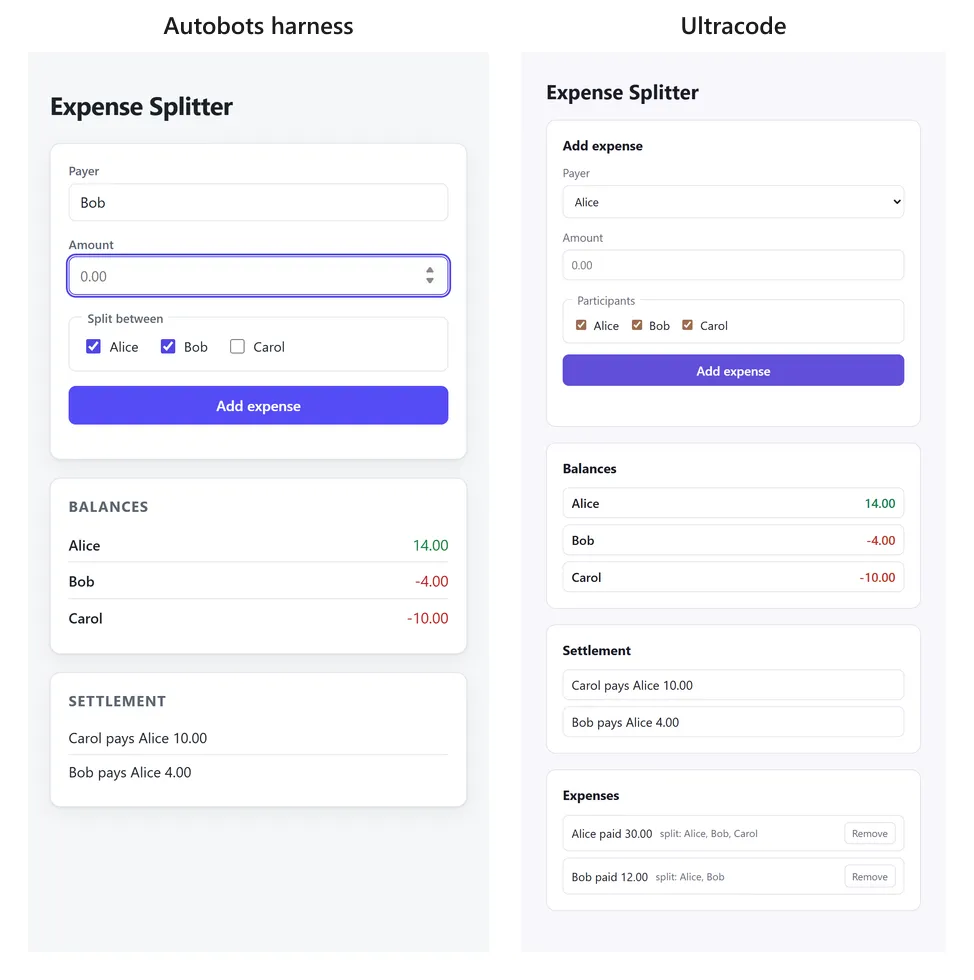
And the expense splitter: the workflow lets me remove an expense I entered by mistake. My harness never built that at all. Most of the rest is a wash.
I knew which build was my own harness, which should have tilted me toward it. I still reached for the workflow’s every time.
What’s left when the orchestration is free
Ultimately the test was a narrow one. The bake-off ran one head-to-head: my harness against the single pattern it happens to be, the adversarial review loop. Ultracode isn’t one pattern. Anthropic’s post lays out the patterns it draws from, and the loop I spent a month on is one panel in the set.
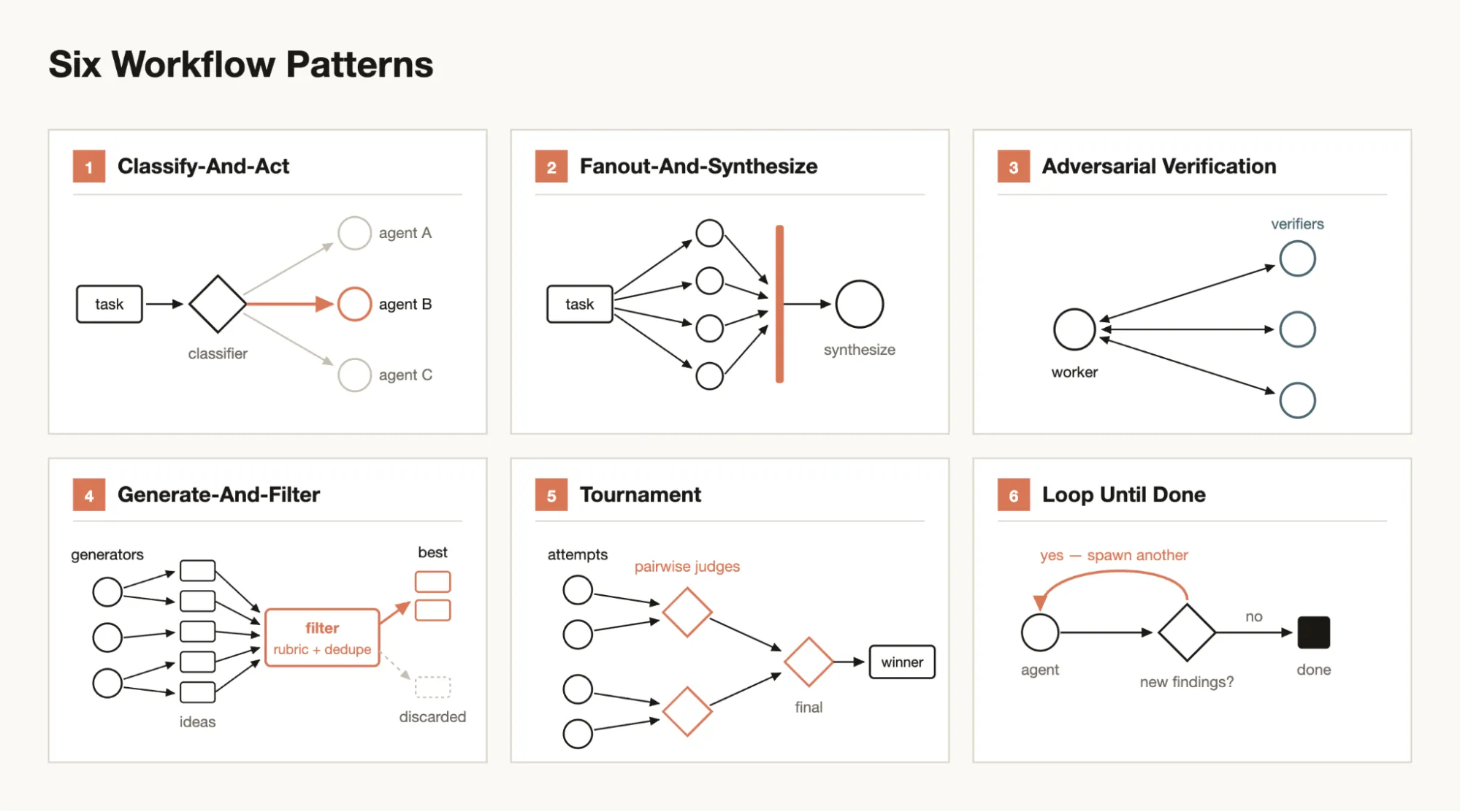
The fact that it can write many more workflows than the one I tested is what makes it so powerful. It also points at what I should focus on now. If I make sure the good practices from my evaluator rubric get injected into the workflows Ultracode writes, I don’t really need the Autobots harness anymore. Ultracode can run the adversarial review loop when a task calls for one, and the rest of the patterns come with it, the fan-out, the loop-until-done, the ones my fixed pipeline was never going to be.
This is the same thing I said before from the other direction. The multi-agent layer was always the smallest part of the system. The bake-off just says even that small part is something I no longer have to build.
The caveats: three apps, all small and self-contained. Longer work, the kind that runs for hours, still might benefit from a more detailed trail, and a workflow doesn’t write one unless I ask. Lastly, I only tested one workflow. Ultracode wins the rest because I have no competition for it.
Summary
- The orchestration is a stock primitive now. The adversarial loop I spent a month on is about ninety lines of dynamic workflow, written per task. On every frozen correctness test, both builds tied.
- The rubric is the only edge, and a rubric is a prompt. The one app the harness won, it won on a quality checklist it carries by default. That checklist pastes into a workflow’s verify step.
- The trail is the real remaining artifact. The record of how the work got made is the thing the workflow didn’t reproduce, and the thing I’d actually miss. And as the models have gotten better, I’ve needed it less and less.
- Small tasks under-test all of this. Three short builds can’t speak for work that runs for days. That’s the next thing to check.
I’ll probably deprecate the harness. I’m glad I built it. I think next I’ll have to figure out how to be creative in improving every workflow version Ultracode provides. Moments like this make it feel hard to keep up with the industry, but at least the learning opportunity has been great.